vibe coding这个词之前一直很火,尤其在编程领域,几乎成了大家耳熟能详的词。
vibe coding最早是由Andrej Karpathy提出,他之前就职于特斯拉,后来做了OpenAI的研究员,最近几年又自己出来做AI方面的教育,他最近在YC的演讲值得去看看,不得不说,把教育做好的人做的演讲也挺有趣。

vibe coding翻译过来叫「沉浸式编程」——通过与LLM交互,指导LLM去完成编程。这看上去是一种挺爽的体验,就像你使用AI工具去代写作业一样,但从编程的精确性角度来说,LLM依然会产生错误,看似顺畅的交互,最终往往会产生难以修复的bug。不过随着模型能力的逐步提升,这些情况会减少,但可能依然存在。
比如今年5月份,我使用cursor来vibe coding了几个项目,当时使用的是Atheropic公司的sonnet4和google的Gemini 2.5 pro,也算是当时世界上头部的LLM,但总体体验下来还是挺痛苦的,经常遇到一些难以解决的问题,为了修复一个bug,花费几个小时却无疾而终。
当然,经过不断的调整、优化提示词,某些问题最终得到了解决,但最终构建出来的production依然不太稳定,同时整体的代码结构也很复杂,根本看不懂。
这次,我选择使用OpenAI的codex CLI,使用下来体验不错,遇到问题也能快速修复,有时候还能给出意想不到的结果。当然,这次使用codex 更多是对之前项目的优化、迭代,所以花的时间比较少,而且由于之前的vibe coding经历,我追求的只是稳定、简洁的function。
这种心态或者说要求的转变,其实是我对自己和大模型边界了解深入的体现。vibe coding就像你和一个(女)朋友在手机上聊天,由于隔着屏幕,你们互相看不到对方的表情和语音变化,所以经常需要互相猜测对方发这句话表达的深层含义,以及背后折射的情绪,尤其中文博大精深,更是容易产生不同的结果。

LLM本质上还是基于概率来理解、推断你真正表达的意思,并给出当前聊天场景下最大可能性的回复,你以为他很懂你,其实他不过是在预测你的预判或者你期待回复的内容而已。
有了AI tools,我们对「结果的贪婪」会被无限放大。以前自己不会的话,要么请教他人、自学,要么就此放弃,现在是什么呢?
我不仅不愿承认自己不会,还会对LLM提出高要求标准。我不看过程,只想要一个确定的结果,甚至有时候还会对别人认真做出来的东西嗤之以鼻。
比如我看到某个UI做得很low,自然而然在心里嘀咕一句:“这破玩儿也能上线?”但其实真要叫自己动手纯敲代码,怕连编辑器都不知道怎么打开。所以,未来网上一定会充斥着一大批非专业人员到处「瞎喷」。当大家都以为自己懂了的时候,那才是最可怕的,勇于承认自己的无知有时候还挺难。
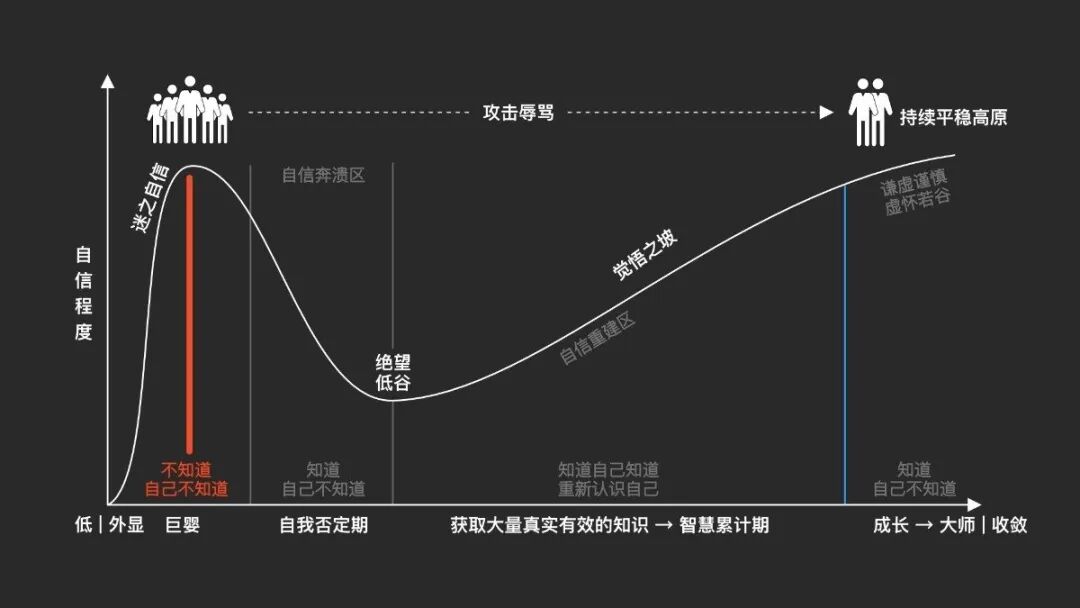
说直白一些,LLM会让很大一群人,比如我,快速的成为「巨婴」——不知道自己不知道。如果这群人去辩论,一定会拿出「AI是这么说的」作为证据,而且「一定会」存在「模型使用鄙视链」,在国内能使用国外LLM的人会说使用国内开源模型产生的结果不可信,同时使用国外LLM的人中,付费使用的又会说:“那是你没有使用200美元的。”别笑,这个我之前还真遇到过。
以后人类的辩论很大概率会成为模型之间的辩论,而人充当的是「传音筒」。A说模型是这样说的,B会回答,但模型却这样看,想想也挺搞笑的——只存在于人之间的争论也会逐渐演化到大模型身上。
我的第一个完整可上线的iOS app:
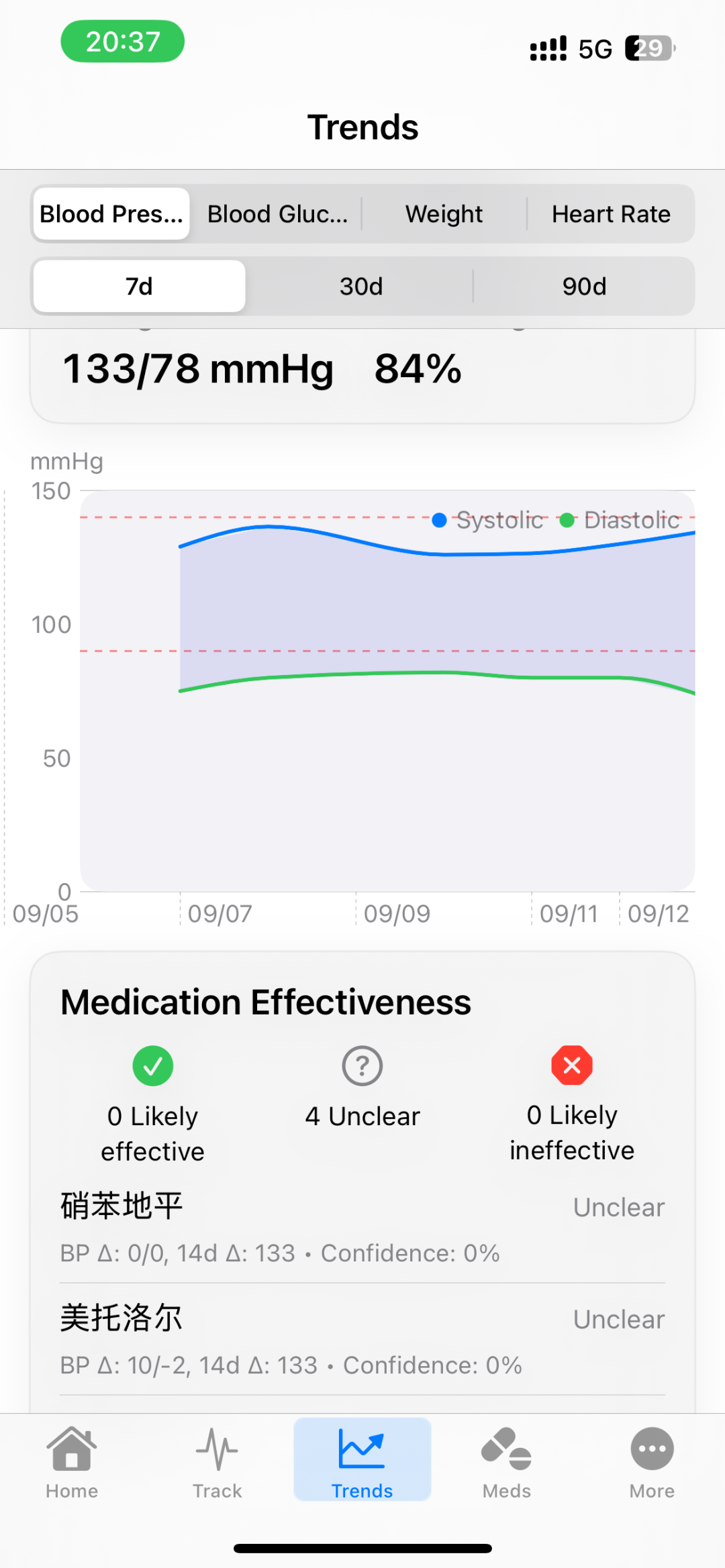
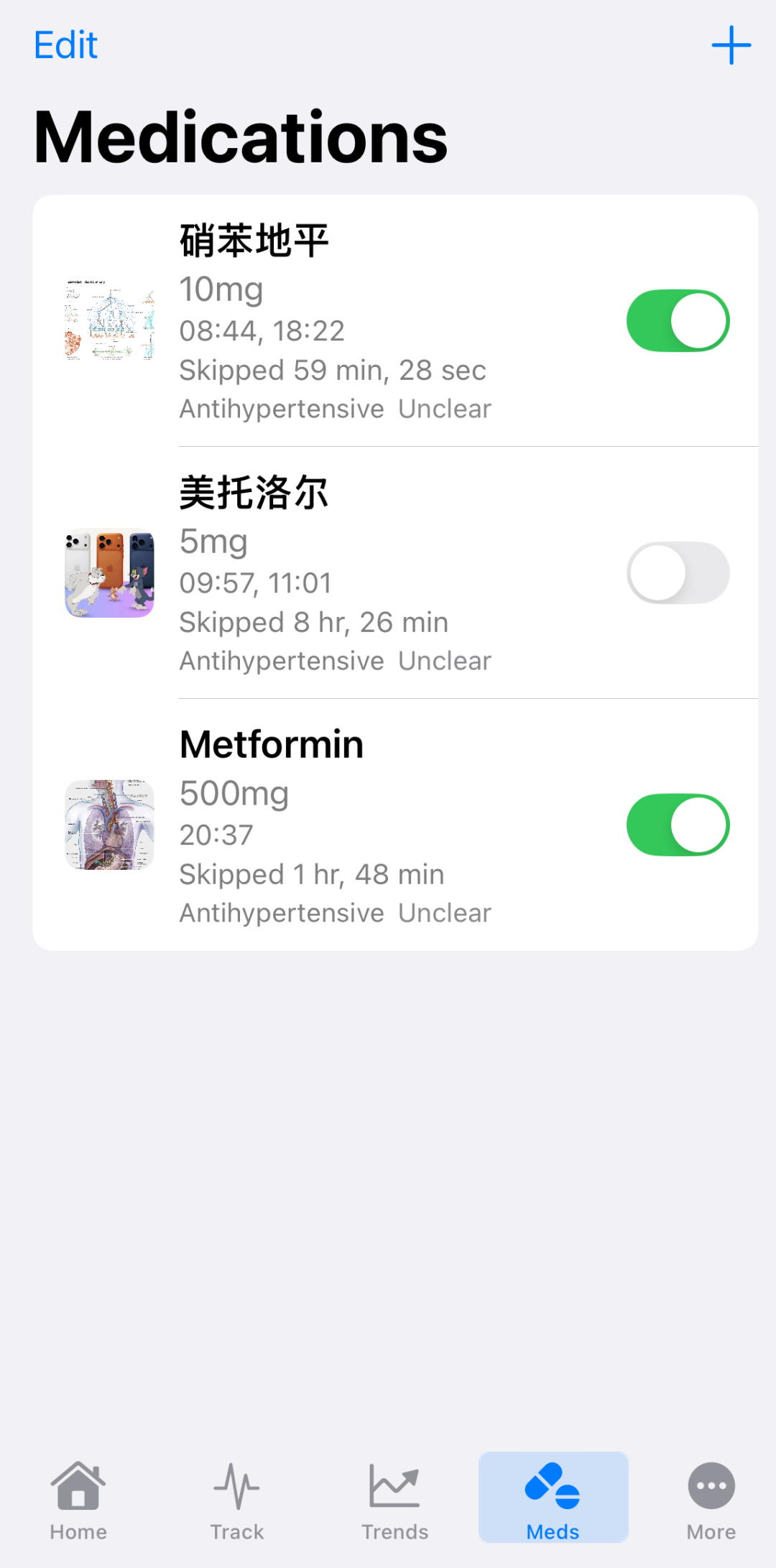
这个app焦距于慢性病健康管理,它来源于我过去在社区实习的经历,我当时发现人们对于用药和健康监测的不重视,导致血压和血糖控制不佳,从而产生了一些并发症。所以,我就想着自己能不能做一个工具来解决这个问题,通过不断的倒腾,我当时是弄了一个网页版本,由于不太稳定就没有继续完成下去,这次选择了重做,尽管目前依然还处在demo阶段,但已经成为了一个可用的产品。
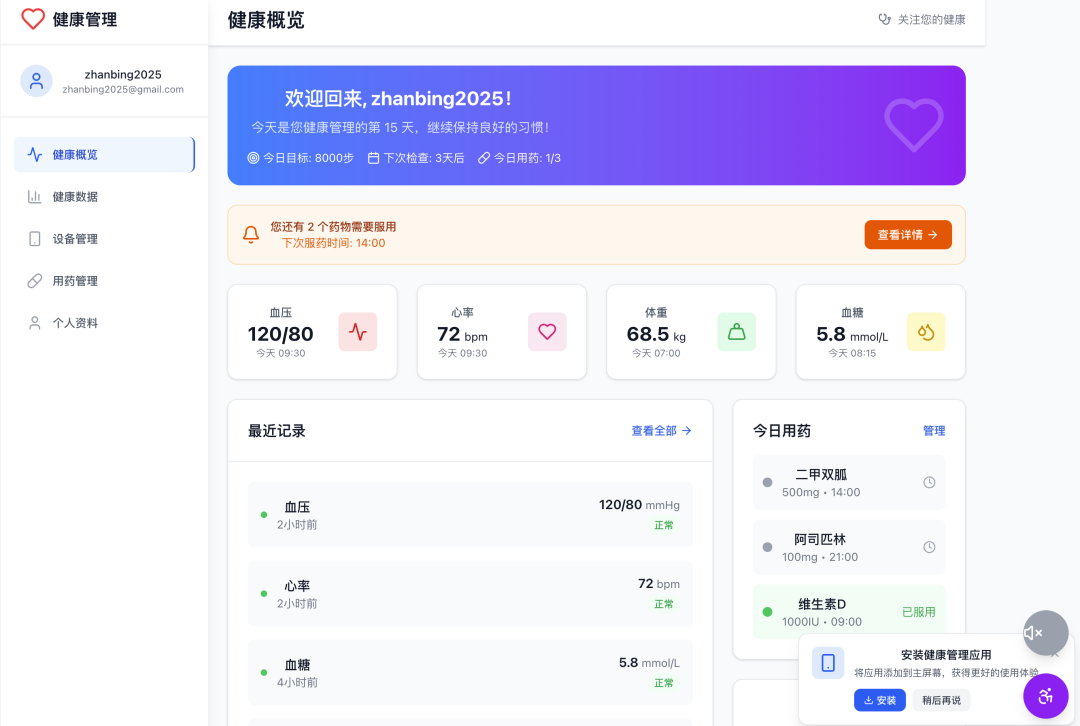
这是我之前做的第一版,总体上挺花哨的,但用起来嘛,嗯,你懂的。
If this post was useful, share it with someone who might need it.